
[vgwort line=“44″ server=“vg05″ openid=“8359f0e60cc9478284d14251ed4c7f04″]
Bots, Crawler oder Spider sind Computer die das World Wide Web nach Inhalten mit unterschiedlichen Zielsetzungen durchforsten. Die bekanntesten sind sicher die Crawler der großen Suchmaschinenbetreiber Bing / MSN, Baidu, Google, Yahoo oder Yandrex. Dass deren Crawler regelmäßig vorbei schauen ist wichtig, damit eine Seite in den Suchergebnissen gefunden wird. Aber es gibt auch zahlreiche andere Crawler, deren Besuch mehr oder weniger sinnvoll ist. Wenn ein Portal keine Stellenangebote beinhaltet, ist es wenig sinnvoll, dass ein Crawler die Seiten regelmäßig besucht. Falls Sie keinen Shop betreiben, hilft es nichts, dass ein entsprechend spezialisierter Crawler Ihre Web-Seiten durchsucht.
Ob ein Crawler ein Portal durchsucht und welche Verzeichnisse durchsucht werden, kann bei kooperativen oder freundlichen Crawlern anhand des Robots Exclusion Standard über eine Datei robots.txt (Kleinschreibung beachten) im root-Verzeichnis gesteuert werden.
Unkooperative oder unfreundliche Crawler ignorieren den Inhalt der robots.txt. Gegen diese Crawler helfen nur stärkere Geschütze.
Die Zugriffe der letzten Tage auf dieses Blog habe ich hinsichtlich der besuchenden Bots, Crawler und Spider ausgewertet. Von Anfang des Monats bis heute, entfallen etwa 15% bis 20% der Seitenabrufe (Hits im Webalizer) auf über 50 verschiedene Crawler.[ref]Hierbei ist zu bedenken, dass es auch Kameraden gibt, die Web-Seiten mit dem User-Agent eines Crawlers abrufen um ihrer Zugriffe zu tarnen. Diese Zugriffe habe ich bei der Betrachtung nicht gefiltert. Einige Seiten verwenden einen Zugriffschutz oder verhindern, dass die Seiten auf anderen Rechnern – z.B. zum Offline Lesen – gespiegelt werden. Damit Google die Seiten trotzdem indizieren kann, werden die Crawler von Google geduldet. Bei einer fehlerhaften Implementierung dieses Schutzes kommt ein Angreifer mit dem User-agent-string eines GoogleBot ebenfalls Zugriff auf die Seiten.[/ref] Der User-agent-string, mit dem sich der Bot, Crawler oder Spider im HTTP-Abruf meldet, ist nicht identisch mit dem User-agent in der Datei robost.txt, nach dem er sucht. Deshalb muss zu jedem Crawler der passende User-agent für die Datei robots.txt gefunden werden. Gute Web-Portale haben eine umfassende Beschreibung des Verhaltens ihrers Crawler; weniger gute verweisen auf die allgemeine Beschreibung der Datei; manche vergessen dabei den User-agent anzugeben, auf den ihr Crawler hört.
Die Bezeichnung „Standard“ ist für den Robots Exclusion Standard ist im Grunde eine Übertreibung. Die Syntax der Datei robots.txt ist nicht sehr streng definiert. Bei der Auswertung der Datei robots.txt sollte der Crawler die Groß-Kleinschreibung bei der Feldnamen (User-agent, Disallow …) und bei seinem Namen (wohlgemerkt sollte) nicht beachten. Als Parameter sind nur User-agent und Disallow definiert und es gibt nur die Wildcard „*“ für den User-agent. Viele Crawler akzeptieren aber auch Erweiterungen wie reguläre Ausdrücke. Einen einheitliche Art der Auswertung der Datei durch die Crawler wurde leider nie definiert. Eine gute Beschreibung des „Minimum“ anhand einer Beispiel-Site findet sich bei bjoernsworld.de · Suchmaschinen.
Hier nun eine Auflistung, kurze Beschreibung und Bewertung der Bots, Crawler und Spider, die ich in der letzten Zeit identifiziert habe.
200PleaseBot/1.0
User-agent-string: Mozilla/5.0 (compatible; 200PleaseBot/1.0; +http://www.200please.com/bot)
Der 200pleaseBot ist ein Crawler von 200please, der die Performance einer Seite prüft. Sie versprechen in der Regel nicht mehr als 100 HTTP-Anfragen pro Monat zu erzeugen. Wer nicht mehr in die Performancemessungen einbezogen werden will, der kann sich per Mail an die Betreiber wenden.
Es gibt acht über die Welt verteilte Server, deren IP-Adressen der Betreiber auch bekannt gibt, mit denen die Performance gemessen wird. Ein historischer Bericht sieht dann etwa wie folgt aus:
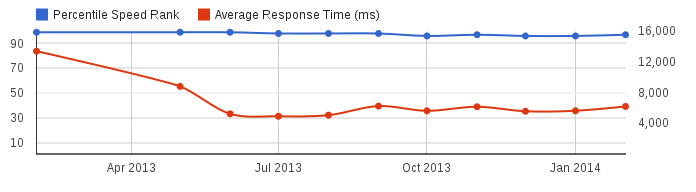
Die Messwerte für meine Server erscheinen mir allerdings sehr unrealistisch. Andere Monitore liefern deutlich bessere Ergebnisse.
Die robots.txt wird nicht ausgewertet, was bei diesem Crawler auch wenig sinnvoll wäre, da er nur die Performance misst und dies auch durch regelmäßiges Lesen er robots.txt tun könnte.
Aussperren? Hier erfährt der Web-Master etwas über die Performance des eigenen Servers aus der Sicht eines Dritten. Der geringe Traffic ist wohl zu verkraften. Aussperren lohnt sich nicht. Da der Crawler nur die Performance misst, sehe ich keinen Bedarf ihn zu sperren.
AhrefsBot/5.0
User-agent-string: Mozilla/5.0 (compatible; AhrefsBot/5.0; +http://ahrefs.com/robot/)
Der AhrefsBot wird von ahrefs betrieben. Der Crawler sucht nach Links in den Web-Seiten und wertet die Backlinks auf eine Seite aus. Der Bot wertet die robots.txt aus. Mit dem spezifischen Parameter Crawl-Delay kann die Zeit zwischen zwei Zugriffen gesteuert werden. Beispiel robots.txt:
robots.txt
user-agent: AhrefsBot
disallow: /
Crawl-Delay: 2
Eine grafische Auswertung sieht z.B. wie folgt aus:
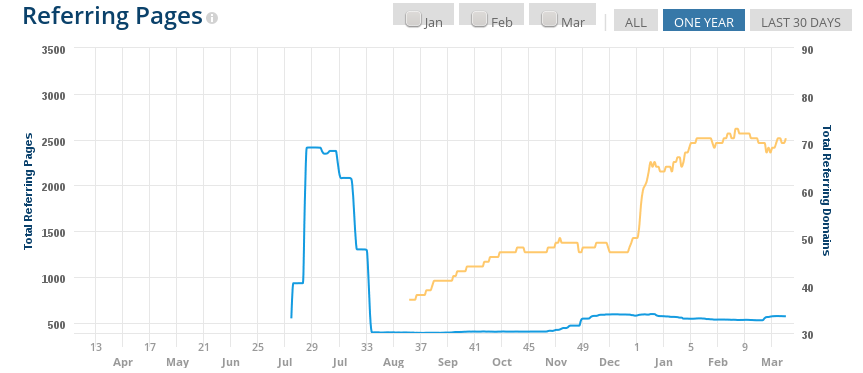
Warum die Backlinks im August 2013 drastisch gesunken sind? Gute Frage, nächst Frage.
Aussperren? Wer nicht möchte, dass Dritte erfahren wohin die eigenen Seiten verlinkten, kann den Bot aussperren.
archive.org_bot
User-agent-string: Mozilla/5.0 (compatible; archive.org_bot; Wayback Machine Live Record; +http://archive.org/details/archive.org_bot)
Mit dem archive.org_bot werden Web-Seiten durch das Internet Archive abgerufen und archiviert. Der Crawler respektiert zwar die robots.txt, aber ich musste mich über die FAQ zur Seite Removing Documents From the Wayback Machine hangeln, um zu erfahren, was ich in der robots.txt eintragen muss. Hier das Ergebnis:
robots.txt
User-agent: ia_archiver
Disallow: /
Aussperren? Wer nicht möchte, dass seine Seiten für die Ewigkeit erhalten bleiben, kann ihn mit der robots.txt aussperren und alte Einträge in
AskPeterBot
User-Agent: Mozilla/5.0 (compatible; AskPeterBot; +http://www.askpeter.de/bot.html)
AskPeter setzt mehrere Crawler für verschiedene Zwecke ein. Um den Crawler mit der robots.txt zu steuern wird folgender Eintrag empfohlen:
robots.txt
User-agent: AskPeterBot
Disallow: /
oder
User-agent: AskPeterBot
Disallow: /verzeichns1/
Disallow: /verzeichns2/
Eine andere Methode ist einen Fehler 401 oder 410 zurück zu geben. Dies wäre mit dem Apache mittels Rewrite-Rules sehr gezielt in einer Datei .htaccess möglich.
Aussperren? Mit den großen Suchmaschinen ist sie nicht vergleichbar. Ich habe sie in der Vergangenheit ausgesperrt, weil mir die Anfragen zu häufig waren.
BacklinkCrawler
User-agent-string BacklinkCrawler (http://www.backlinktest.com/crawler.html)
Der BacklinkCrawler speist ebenfalls eine Suchmaschine für Backlinks. Wie AhrefsBot beachtet er einen speziellen Parameter Crawl-delay (Achtung! Hier wird delay mit kleinem „d“ geschrieben.)
robots.txt
User-agent: BacklinkCrawler
Disallow: /
Crawl-delay: 10
Um den Bot komplett abzuweisen wird folgender Eintrag durch den Betreiber in der .htaccess empfohlen:
.htaccess
order deny,allow
deny from 46.4.100.231
Baiduspider/2.0
User-agent-string: Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
Baiduspider ist der Crawler der chinesischen Suchmaschine baaidu. Leider enthält die Suchmaschine sehr viele chinesische Zeichen. Neben dem User-agent Baiduspider gibt es weitere User-agents mit den Erweiterungen -image, -video, -news, -favo, -cpro und -ads,
robots.txt
User-agent: Baiduspider
Disallow: /User-agent: Baiduspider-image
Allow: /image/
Will man unliebsame Besucher aussperren, die nur vorgeben ein Baiduspider zu sein, so kann man einen echten Baiduspider über die Rückwärtsauflösung der IP-Adresse erkennen. Der Name sollte z.B baiduspider-123-125-66-120.crawl.baidu.com oder BaiduMobaider-119-63-195-254.crawl.baidu.jp. lauten.
Siehe hierzu die Beschreibung für den GoogleBot.
Aussperren? Wer keinen Wert darauf legt von dieser Suchmaschine gefunden zu werden, sollte sie aussperren. Es mag von Vorteil sein, nicht von chinesischen Hackern einfach gefunden zu werden. Nennenswerten Traffic verursacht sie nicht, aber dies schwankt auch stark.
bingbot/2.0
User-agent-string: Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)
Der bingbot ist der Crawler der Suchmaschine Bing, der Microsoft Suchmaschine. Mit dem Link im User-agent-string geht die Sucherei erst los. So ziemlich das schlechteste, dass mir bisher begegnet ist. Da ist sogar eine Seite mit chinesischen Zeichen informativer. Unter „Advanced topics“ der Seite webmaster help & how-to finden sich dann die gewünschten Informationen.
Die Beschreibung über die Datei robots.txt ist allgemein gehalten und den korrekten User-agent finden wir hier nicht. Außerdem sollte der Abschnitt „User-agent: *“ der letzte Bolg in der Datei sein, da die Crawler nach dem ersten Treffer aufhören weitere Abschnitte zu suchen. In der Robots Database gibt es keinen Eintrag für Bing.
Ein BingBot kann über eine Reverse und Forward DNS Abfrage idenitifiziert werden. Der Name für die IP Adresse 157.55.33.18 sollte z.B. wie folgt lauten: msnbot-157-55-33-18.search.msn.com.
Näheres siehe wieder unter GoogleBot
Aussperren? Welche Frage. Wer von einer der größten Suchmaschinen nicht gefunden werden will, kann sie aussperren.
Möglicherweise ist aber eine Einschränkung bestimmter Verzeichnisse sinnvoll. In einem WordPress-Blog schränke ich die Indizierung wie folgt ein.
robots.txt
User-agent: *
Disallow: /wp-register.php
Disallow: /wp-login.php
Disallow: /wp-admin/
Disallow: /wp-content/plugins/
Darüber hinaus könnten auch die Verzeichnisse „/tags/“ und „/topics/“ ausgenommen werden. Da diese Seiten nicht zu einzelnen Artikeln sondern zu Stichworten und Kategorien führen.
BLEXBot/1.0
User-agent-string: Mozilla/5.0 (compatible; BLEXBot/1.0; +http://webmeup-crawler.com/)
Der BLEXBot Crawler hat sogar eine eigenen Domain für seine Beschreibung, die knapp aber umfassend ist. Er akzeptiert die Datei robots.txt und die Betreiber versprechen die niemals die Performance einer Seite zu beeinträchtigen, indem sie maximal eine Anfrage pro drei Sekunden senden und bei langsamen Antworten die Abfragen beenden. Ziel ist die Sammlung für Internethändler in der Analyse von Linkstrukturen zu helfen. Kurz: Es geht um Search Engine Optimization (SEO). SEO ist bis zu einem gewissen Grad sinnvoll. Z.B. wenn es darum geht eine Seite für Crawler geeignet aufzubauen. Darüber hinaus hilft guter Inhalt. Andere „Optimierungen“, die nicht auf der eigenen sondern auf fremden Seiten stattfinden, z.B. Link-SPAM sind wenig sinnvoll und hilfreich. Die Leistungen von webmeup sind allerdings anmelde und kostenpflichtig. Auch eine Anmeldung über Facebook mit der Ablieferung der Freundesliste und eigenen E-Mailadresse ist möglich.
robots.txt
User-agent: BLEXBot
Disallow: /private/
Disallow: /messages/
# oder
Disallow: /
Crawl-delay: 10
Aussperren? Habe den Crawler diesen Monat erstmals gesehen. Hat so ziemlich die gesamte Seite durchsucht. Schau wir mal.
BUbiNG
User-agent-string: BUbiNG (+http://law.di.unimi.it/BUbiNG.html)
BUbiNG ist ein skalierbarer, voll verteilter Crawler, der zur Zeit vom Laboratory for Web Algorithmics (LAW) entwickelt wird und den UbiCrawler ablösen soll.
Die mit dem folgenden regulären Ausdruck lassen sich die Hostnamen der Server erkennen / filtern:
s[0-9]+.law.di.unimi.it
robots.txt
Die robots.txt wird beachtet. Das bereitgestellte Beispiel ist minimalistisch. META Tags in den Web-Seiten werden nicht ausgewertet.
User-agent: BUbiNG
Disallow: /
CareerBot/1.1
User-agent-string: Mozilla/5.0 (compatible; CareerBot/1.1; +http://www.career-x.de/bot.html)
Der CareerBot gehört zu Career-X. Die Seite lädt extrem langsam bis gar nicht. Career-X such nach Jobangeboten im Internet. Beispiel robots.txt:
robots.txt
User-agent: careerbot
Disallow: /news/
Aussperren? Wenn keine sinnvollen Informationen für diesen Crawler auf der Seite vorhanden sind: Ja. Der Crawler kommt allerdings alle drei Tage vier Mal vorbei und schaut nach der robots.txt.
Cliqzbot/0.1
User-agent-string: Cliqzbot/0.1 (+http://cliqz.com/company/cliqzbot)
Cliqz ist ein Münchner Startup, das daran arbeitet, den Weg wie Nutzer Web-Seiten finden und entdecken zu verbessern. Es wäre schön, wenn sie ihre eigene Web-Seite entdecken und mit Informationen füllen würden. Für den Anfang schlage ich mehr Informationen über den CliqzBot vor.
Bei Abruf der robots.txt meldet er sich kurz und knapp mit den User-agent-string Cliqzbot. Ich gehe mal davon aus, dass er darauf hört.
Aussperren? Nur sehr wenig Traffic – 30 Seiten. Fast jeder Abruf kommt von einer anderen IP-Adresse. Nach dem Abruf der robots.txt folgte Tage bevor weitere Seiten abgerufen werden. Mir ist nicht klar wonach der Bot sucht. Aufwand lohnt zum sperren lohnt nicht. Die Seiten findet sicher auch im Google Cache.
CMS Crawler
User-agent-string: Mozilla/4.0 (CMS Crawler: http://www.cmscrawler.com)
Der CMS Crawler identifieziert welche Tools eine Web-Seite nutzt. Sie liefern auch Listen zu ihren Ergebnissen. Sicher für Black Hats nicht ganz uninteressant. Keine Information über die Beachtung der robots.txt gefunden. Diese wurde allerdings auch nie abgerufen, als ist die Antwort wohl nein.
Aussperren? Nur ein Zugriff alle paar Tage auf der Startseite „/“ von der Adresse 83.233.207.74. Aufwand lohnt nicht.
DoCoMo/2.0 oder SAMSUNG-SGH-E250/1.0
User-agent-string: DoCoMo/2.0 N905i(c100;TB;W24H16) (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)
User-agent-string: SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 …
Dieser Crawler gehört eindeutig Google, die IP-Adressen lösen zu crawl-(IP).googlebot.com. auf. Mit diesem User-agent-string wird allerdings nicht die robots.txt abgerufen. Der erste Teil, DoCoMo/2.0 N905i(c100;TB;W24H16), bezeichnet angeblich verschiedene Mobilfunkgerätetypen. Hier wohl ein Mobilfunkgerät des Firma K.K. NTT DoCoMo.
Aussperren? Siehe Google.
DotBot/1.1
User-agent-string: Mozilla/5.0 (compatible; DotBot/1.1; http://www.opensiteexplorer.org/dotbot, help@moz.com)
Bot einer SEO Seite. Für 99$ pro Monat gibt es professionelle Statistiken über die Backlinks etc.
robots.txt
User-agent: dotbot
Disallow: /admin/
Disallow: /scripts/
Disallow: /images/
Exabot/3.0
User-agent-string: Mozilla/5.0 (compatible; Exabot/3.0 (BiggerBetter); +http://www.exabot.com/go/robot)
Der Exabot ist der Crawler der Firma Exalead. Eine nette Suchmaschine, die zum Suchergebnis ein Thumbnail des Seite liefert.
robots.txt
User-agent: Exabot
# To prevent indexing of pages from a particular directory (for example, football)
Disallow: /football
# To prevent indexing of a particular file type (.gif, par exemple)
Disallow: *.gif$
# To prevent indexing of dynamic pages
Disallow: *?
# You can also specify a desired crawl-delay
Crawl-delay: 10
IP-Adressen lösen nach „crawl(Nr).exabot.com.“ auf.
Aussperren? Gute Frage. Wenig Traffic. Nichts böses.
fastbot.de crawler 2.0 beta
User-agent-string: fastbot.de crawler 2.0 beta (http://www.fastbot.de)
Ein weiterer Versuch einer deutschen Suchmaschine. Die Ergebnisse sollen weniger Spam enthalten, sind aber deutlich veraltet und wenig treffsicher.
Aussperren? Nur eine Abfrage im Zeitraum. Nicht der Rede wert.
Flamingo_SearchEngine
User-agent-string: Flamingo_SearchEngine (+http://www.flamingosearch.com/bot)
Dies ist eine spezielle Suchmaschine nur Nachrichten. Der Crawler folgt der robots.txt. Wer Fragen zum Crawler hat, kann eine E-Mail an bot _ at _ flamingosearch.com schicken. Ein Beispiel für die robots.txt wird nicht gegeben.
Googlebot/2.1
User-agent-string: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Der Googlebot ist der Bot der Firma Google. Allerdings nutzen auch Kriminelle gerne diesen User-agent-string um ihre Angriffe als Googlebot zu tarnen.
Aussperren? Natürlich nicht. oder? Vor falschen Googlebots gibt es einen einfachen Schutz, wie ich in dem Artikel falsche Bots findenschützen.
Googlebot-Image/1.0
User-agent-string: Googlebot-Image/1.0
Aussperren? Siehe Googlebot/2.1.
GrapeshotCrawler/2.0
User-agent-string: Mozilla/5.0 (compatible; GrapeshotCrawler/2.0; +http://www.grapeshot.co.uk/crawler.php)
oder
User-agent-string: Mozilla/5.0 (compatible; grapeFX/0.9; crawler@grapeshot.co.uk
Grapeshot assists advertisers to contextually place adverts on pages, to do this it is necessary to examine, or crawl, the page to determine which category, or categories, it best matches (more general details on this bit are available here).
robots.txt
User-agent: grapeshot
Disallow: /private/
Disallow: /messages/
Aussperren? Da ich keine Werbung auf dieser Seit habe, ist der Crawler hier falsch. Also aussperren. Allerdings lohnt der Traffic nicht die Mühe.
ia_archiver
User-agent-string: ia_archiver (+http://www.alexa.com/site/help/webmasters; crawler@alexa.com)
Der ia_archiver ist der Crawler der Alexa.com, die den Rang einer Seite nach schwer durchschaubaren verfahren ermittelt. Der Name des User-agent ist nun dummerweise mit dem Namen des User-agent des Internet Archive identisch. Siehe oben.
Aussperren? Wer auf eine Rang bei Alexa verzichten kann, kann sicher auch auf den Crawler als Besucher verzichten.
iCjobs Stellenangebote Jobs
User-agent-string: Mozilla/5.0 (X11; U; Linux i686; de; rv:1.9.0.1; compatible; iCjobs Stellenangebote Jobs; http://www.icjobs.de) Gecko/2010040
iCjobs ist eine weitere Stellenbörse in deutschen Landen.
robots.txt
Der User-agent ist etwas seltsam mit Leerzeichen und Bindestrich, so von der Homepage kopiert.
User-agent: ICCrawler – iCjobs
Disallow: /
Aussperren? Wenn keine Stellenanzeigen auf der Seite, dann braucht der Crawler auch nichts zu suchen. Ansonsten kann man ihn gezielt nur Stellenangebote suchen lassen. Bei mir wirkt es , er schaut aber gerne alle zwei Wochen nach der robots.txt.
Infohelfer/1.3.3
User-agent-string: Mozilla/5.0 (compatible; Infohelfer/1.3.3; +http://www.infohelfer.de/crawler.php)
Der Infohelfer gehört zu einer weiteren deutschen Suchmaschine. Die Beschreibung des Crawlers ist eher eine Nicht-Beschreibung. Zwar hört er angeblich auf die robots.txt, aber es wird nicht erwähnt, wie der User-agent heißt, nach dem er sucht.
Aussperren? Da der Crawler über die IP-Adresse 5.9.88.119 die robots.txt abfragt, ist er bei mir ausgesperrt. Aus diesem Adressbereich (5.9.0.0/16) bei Hetzner kommt hauptsächlich Müll. Dies hindert jedoch nicht daran von anderen Adressen mit dem User-agent-string „infohelfer/0.9 (http://www.infohelfer.de/)“ auf die Seiten zuzugreifen. Diese IP-Adressen lösen rückwärts zu crawl-(ip).infohelfer.de auf.
linkdexbot/2.0
User-agent-string: Mozilla/5.0 (compatible; linkdexbot/2.0; +http://www.linkdex.com/about/bots/)
Der linkdexbot ist ein Crawler für SEO.
Linkdex will respect the crawl frequency limitation you have outlined in your robots.txt file. We also crawl relatively slowly, often waiting up to 5 seconds between pages. This ensures your website’s performance is not affected in any way.
Also wird Crawl-delay ausgewertet, Disallow nicht? Es fehlt leider die Angabe auf welchen Name er hört; vielleicht linkdexbot.
Aussperren? Ja. Soweit ich es kursorisch geprüft habe nur für angemeldete Nutzer.
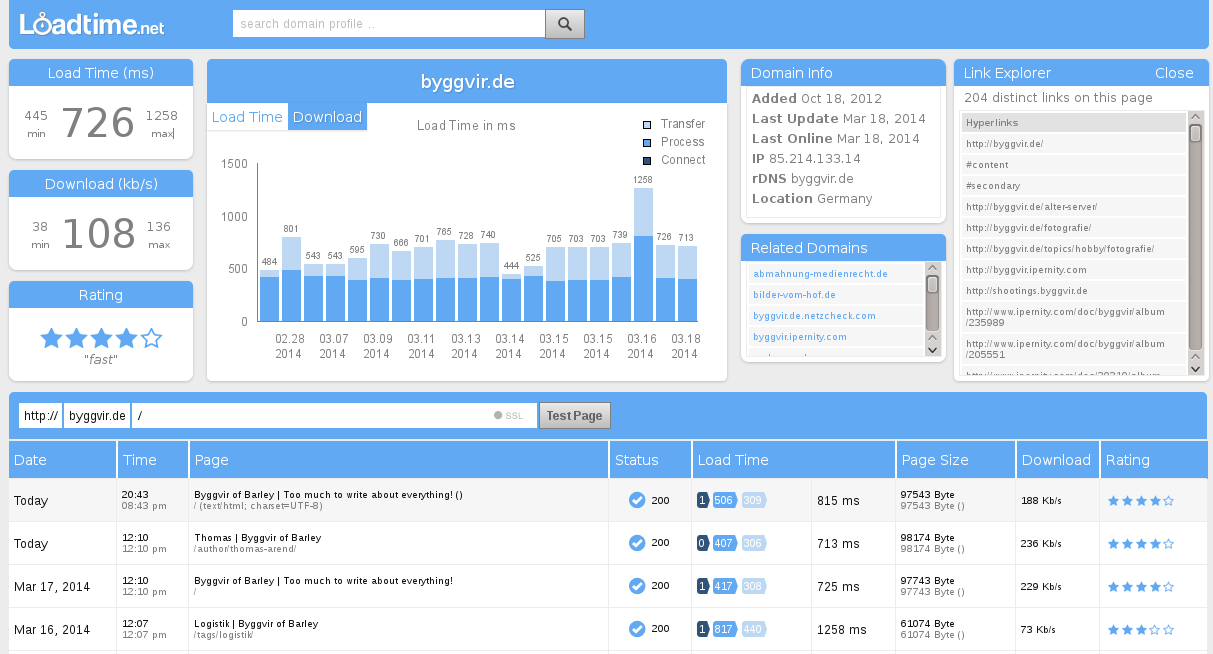
LoadTimeBot/0.9
User-agent-string: Mozilla/5.0 (compatible; LoadTimeBot/0.9; +http://www.loadtime.net/bot.html)
The goal of this project is to create a detailed database of load time data over time for publicly accessible websites. Damit enstpricht der LoadTimeBot Crawler dem 200PleaseBot. Die Auswertung auf der Homepage ist allerdings umfangreicher und die Messwert weichen extrem von denen bei 299Please ab. Die Datei robots.txt wird beachtet, jedoch nicht regelmäßig abgerufen. Welchen User-agent der Crawler erwartet wird nicht beschrieben; Hinweise zum Format der robots.txt fehlen.
Aussperren? Hier erfährt der Web-Master etwas über die Performance des eigenen Servers aus der Sicht eines Dritten. Der geringe Traffic ist wohl zu verkraften. Aussperren lohnt sich nicht.
magpie-crawler/1.1
User-agent-string: magpie-crawler/1.1 (U; Linux amd64; en-GB; +http://www.brandwatch.net)
Aufgabe des magpie-crawler ist es Informationen zu Marken im Internet zu sammeln. Dies ist nur für Unternehmen interessant.
Zitat: Many large companies use our services to listen to what people think about their brands, products and services, so there’s a good chance your opinion will be heard.
robots.txt
Die Beschreibung der robots.txt findet man am schnellsten über die Google Suche. Hat man sie gefunden, ist sie dürftig.
User-agent: magpie-crawler
Disallow: /
Aussperren? Lohnt sich, wenn es nichts zu Marken gibt.
Mail.RU_Bot/2.0
User-agent-string: Mozilla/5.0 (compatible; Linux x86_64; Mail.RU_Bot/2.0; +http://go.mail.ru/help/robots)
Der Crawler Mail.RU ist der Bot der russischen Seite mail.ru. Wer des Russischen nicht mächtig ist, muss Google Translate nutzen.
robots.txt
Der Crawler akzeptiert die robots.txt mit zahlreichen Erweiterungen wie Allow, Host, Sitemap, Clean-param und Craws-delay. Sogar reguläre Ausdrücke werden unterstützt. Sehr gute Dokumentation, auch wenn die Übersetzung durch Google etwas problematisch ist.
User-agent: Mail.RU_Bot
# oder
User-agent: Mail.RU
Disallow: / cgi-bin
Disallow: / add
Allow: / add / top
Disallow: / add / top / private
Aussperren? Muss jeder selbst wissen. Aber man kann die Suchergebnisse mit der robots.txt sicher gut beeinflussen.
MiaDev/0.0.1
User-agent-string: MiaDev/0.0.1 (MIA Bot for research project MIA (www.MIA-marktplatz.de); http://www.mia-marktplatz.de/spider; spider@mia-markt
Der MiaDev Crawler gehört zu einem Forschungsprojekt „MIA“ und wird vom Bundesministerium für Wirtschaft und Technologie (BMWi) im Rahmen des Trusted Cloud Programms gefördert.
robots.txt
User-agent: MiaDev
Disallow: /pictures/
Disallow: /personal/
Crawl-delay: 15
Aussperren? Nur sehr wenige Zugriffe, lohnt nicht.
MJ12bot/v1.4.4
User-agent-string: Mozilla/5.0 (compatible; MJ12bot/v1.4.4; http://www.majestic12.co.uk/bot.php?+)
Der MJ12bot ist der Crawler eines weiteren SEO Projektes. Die Auswertung der gesammelten Informationen ist – derzeit – noch frei verfügbar. Majestic12 bieten einen Service, für den auf anderen Seiten recht viel Geld verlangt wird.
robots.txt
Die Robots.txt wird akzeptiert, allerdings nur die einfachen Parameter.
User-Agent: MJ12bot
Disallow: /
Crawl-Delay: 5
Aussperren? Wer keinen Wert auf Backlinks legt kann die Seite aussperren.
MojeekBot/0.6
User-agent-string: Mozilla/5.0 (compatible; MojeekBot/0.6; http://www.mojeek.com/bot.html)
Der Crawler MojeekBot gehört zu einer „aufstrebende“ Suchmaschine im Vereinigten Königreich.
robots.txt
Die Robots.txt wird akzeptiert, allerdings nur die einfachen Parameter.
User-Agent: MojeekBot
Disallow: /
Crawl-Delay: 5
Ob die Crawler echte MojeekBots sind kann über DNS und den Namen crawl-(IP).mojeek.com. geprüft werden.
Aussperren? Normale Suchmaschine.
msnbot/2.0b und msnbot-media/1.1
User-agent-string: msnbot/2.0b (+http://search.msn.com/msnbot.htm)
User-agent-string: msnbot-media/1.1 (+http://search.msn.com/msnbot.htm)
Siehe BingBot.
NetzCheckBot/1.0
User-agent-string: NetzCheckBot/1.0 (security seal; http://byggvir.de.netzcheck.com; bot@netzcheck.com)
Der Crawler NetzCheckBot soll Seiten im Internet auf Sicherheit prüfen. Leider ist eine Beschreibung des Crawlers auf den spartanischen Seiten nicht zu finden. Über den Sinn oder besser Unsinn dieser Checks habe ich bereits berichtet.
niki-bot
User-agent-string: niki-bot
Aussperren? Nur ein Zugriff, da denke ich nicht drüber nach.
oBot/2.3.1
User-agent-string: Mozilla/5.0 (compatible; oBot/2.3.1; +http://filterdb.iss.net/crawler/
Aussperren? Nur drei Zugriffe, da denke ich nicht drüber nach.
PagesInventory
User-agent-string: PagesInventory (robot http://www.pagesinvenotry.com)
Aussperren? Liest robots.txt. Nur drei Zugriffe, (IP 130.185.109.239) da denke ich nicht drüber nach.
proximic
User-agent-string: Mozilla/5.0 (compatible; proximic; +http://www.proximic.com/info/spider.php)
Der Crawler proximic gehört zur PROXIMIC
Zitat: Proximic’s content analysis enables advertising partners to determine the best matching campaign for a page’s content to achieve the highest CPM for you as a publisher. Proximic works with many advertising partners and it is very likely that one of them is serving ads to your site.
robots.txt
Beachtet die Datei robots.txt; interessant ist, dass das Beispiel einen Hinweis gibt, wie dem Spider der Zugriff erlaubt wird, nicht wie er verboten wird. Ein Schelm, wer böses dabei denkt!
# Hier mit wird dem Spider der Zugriff erlaubt!
User-agent: proximic
Disallow:
Aussperren? Zu wenig Zugriffe.
QuerySeekerSpider
User-agent-string: QuerySeekerSpider ( http://queryseeker.com/bot.html )
Auch bei QuerySeeker handelt es sich um ein Web-Seite zur Marktanalyse. Es wird nur der User-agent (eigentlich der User-agent-string) auf der Beschreibungsseite des Spiders angegeben.
robots.txt
Wer den Zugriff nicht möchte, wird gebeten, die Datei robots.txt zu installieren. Weitere Hinweise gibt es nicht.
Aussperren? Nur ein Zugriff, da denke ich nicht drüber nach.
R6_CommentReader und R6_FeedFetcher
User-agent-string: R6_CommentReader(www.radian6.com/crawler)
User-agent-string: R6_FeedFetcher(www.radian6.com/crawler)
Aussperren? ?
SEOkicks-Robot
User-agent-string: Mozilla/5.0 (compatible; SEOkicks-Robot; +http://www.seokicks.de/robot.html)
SEOkicks.de ist eine weitere deutsche Seite zur Analyse der Backlinks. Derzeit stehen mehr als 55 Milliarden Datensätze bereit.
Aussperren? Der Crawler kommt aus einem bei mir komplett gesperrten Netz: Hetzner.
ShowyouBot
User-agent-string: ShowyouBot (http://showyou.com/crawler)
Die Crawler Beschreibung ist nicht vorhanden, liest allerdings zuerst die Datei robots.txt. Auf der Hauptseite wird eine Video / TV App für Apple und Android angeboten.
Aussperren? Zu wenig Zugriffe.
SISTRIX Crawler
User-agent-string: Mozilla/5.0 (compatible; SISTRIX Crawler; http://crawler.sistrix.net/)
Der SISTRIX Crawler beachtet angeblich die Datei robots.txt, was ich nicht bestätigen kann. Er kommt aus verschiedenen Netzen. Ich habe den Zugriff mittels robots.txt vor langer Zeit verboten, was mich allerdings nicht vor ständigen Besuchen schützt. Der Bot kommt mit so vielen Adressen daher, dass eine Blockierung über die IP-Adresse wenig sinnvoll ist.
SISTRIX ist eine SEO Seite, die eine Anmeldung erfordert.
Aussperren? Ja. Nur wie?
socialbm_bot/1.0
User-agent-string: Mozilla/5.0 (compatible; socialbm_bot/1.0; +http://spider.socialbm.net)
Dieser Crawler dient der Prüfung von Bookmarks die Mitglieder des Social Bookmarking.net/ mit der Web-Seite verwalten und teilen können. Rechts auf der Seite werden die zu letzt besuchten Web-Site fortlaufend angezeigt.
Zitat der Seite:
Social-Bookmarking.net is a free online application based on the Pligg Content Management System. It should be used as a bookmarking site where you can organize, store, manage and search bookmarks. Users save links to this platform that they want to remember and/or share with other.
robots.txt
Außer dem Beispiel, wie die Seite komplett ausgesperrt werden kann, keine Informationen über die Datei robots.txt.
User-agent: socialbm_bot
Disallow: /
Aussperren? Nein. 1. Zu wenig Zugriffe. 2. Hier werden nur Bookmarks auf Gültigkeit und Regelkonformität geprüft.
Sogou web spider/4.0
User-agent-string: Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07)
Crawler einer chinesischen Suchmaschine Sogou, die auf der Portalseite Google ähnelt.
Aussperren? Zu wenig Zugriffe.
spbot/4.0.7
User-agent-string: Mozilla/5.0 (compatible; spbot/4.0.7; +http://OpenLinkProfiler.org/bot )
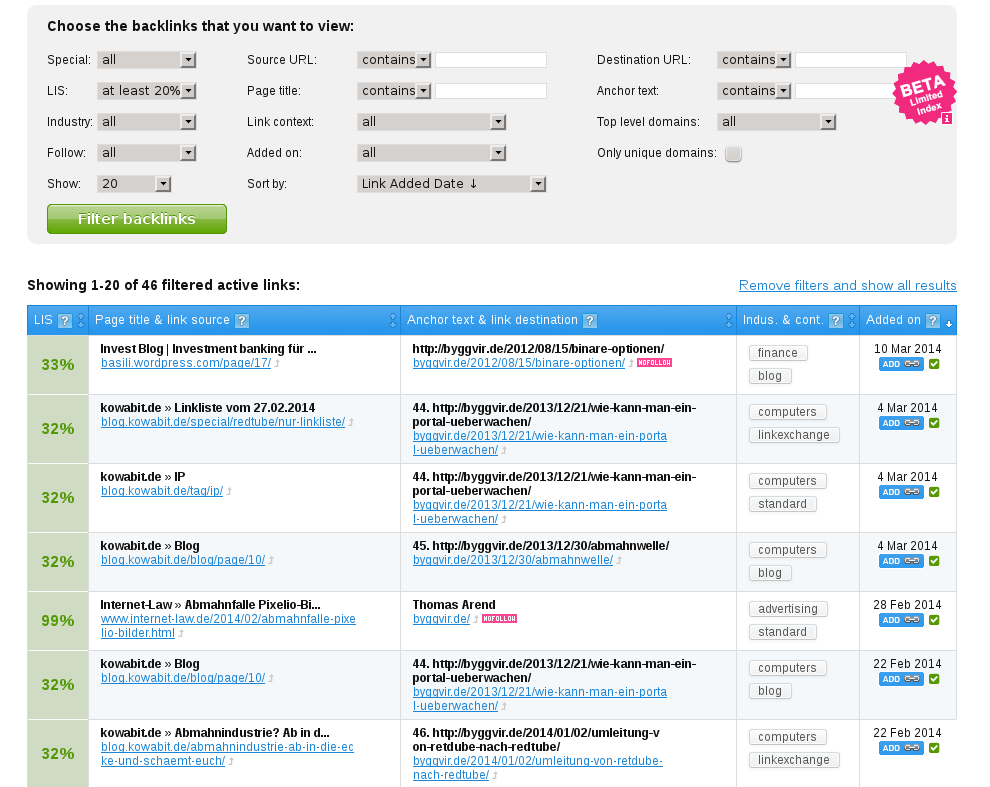
Der Crawler spbot zur Suchmaschine OpenLinkProfiler. Derzeit noch im Beta-Stadium mit reduziertem Speicher für die Datenbank. Hier gibt es (alle) Backlinks kostenlos! OpenLinkprofiler ist die beste Suchmaschine, die ich im Bereich Backlinks gefunden habe.
robots.txt
Gute Beschreibung des Verhaltens der Crawlers. Akzeptiert die Datei robots.txt. Eine Liste der Adressbereiche, aus denen die Bots kommen, ist Online verfügbar. Leider wird nicht beschrieben, ob einen Prüfung über Reserve DNS möglich ist.
User-agent: spbot
Disallow: /
Crawl-delay: 10
Aussperren? Nein. Eigentlich zu wenig Zugriffe um darüber nachzudenken, liefert allerdings sehr gute Ergebnisse zu den Backlinks und dies kostenlos.
ssearch_bot
User-agent-string: ssearch_bot (sSearch Crawler; http://www.semantissimo.de)
Zielnetzwerk ist während ich den Artikel schreibe nicht evrfügbar.
Aussperren? Zu wenig Zugriffe um darüber nachzudenken.
Twitterbot/1.0
User-agent-string: Twitterbot/1.0
Die Geschichte ist hier zu kompliziert. Siehe Twitterbot in der englischen WikiPedia.
Aussperren? Zu wenig Zugriffe um darüber nachzudenken.
URLAppendBot/1.0
User-agent-string: Mozilla/5.0 (compatible; URLAppendBot/1.0; +http://www.profound.net/urlappendbot.html
Der Zweck der Suchmascine ist angeblich zu Frimenname und Telefonnummern die zugehörigen Internet-Präsenz zu finden.
robots.txt
Liest die Datei robots.txt aber keine Beschreibung vorhanden.
Aussperren? Nur acht Zugriffe, da denke ich nicht drüber nach.
WASALive-Bot
User-agent-string: Mozilla/5.0 (compatible; WASALive-Bot ; http://blog.wasalive.com/wasalive-bots/)
Bot der Suchmaschine WASALive.com.
Die Datei robots.txt wird angeblich beachtet (bei mir erfolgten keine Zugriffe auf die robots.txt, nur aug „/“). Einen nähere Beschreibung dazu gibt es nicht.
Aussperren? Nur ein Zugriff, da denke ich nicht drüber nach.
waybackarchive.org/1.0
User-agent-string: Mozilla/5.0 (compatible; waybackarchive.org/1.0; +spider@waybackarchive.org)
Die Domain waybackarchive.org steht zum Verkauf. Ein User-agent-string mit einem Verweis auf diese Domain ist daher etwas seltsam. Auf die Schnelle habe ich nichts positives gefunden.
Aussperren? Fragt sich wie. Zwar wird die robots.txt gelesen, aber wie ist der User-agent. Die IP-Adressen scheinen quer Beet verteilt, ein Reverse DNS ergibt die einen Hinweis auf die Domain spider.spiderlytics.com. Da gibt es auch keine sinnvolle Information. Die Domain ist wieder anonym registriert.
Es könnte sich um einen getarnten Pixray Seeker handeln. Siehe: Freundliche und unfreundliche Crawler
WBSearchBot/1.1
User-agent-string: Mozilla/5.0 (compatible; WBSearchBot/1.1; +http://www.warebay.com/bot.html
Suchmaschine für Preisvergleiche.
User-agent: WBSearchBot
Disallow: /
Aussperren? Wer keinen Shop betreibt, sollte den Crawler aussperren.
yacybot
User-agent-string: yacybot (freeworld/global; amd64 Windows Server 2008 R2 6.1; java 1.7.0_45; Europe/de) http://yacy.net/bot.html
Aussperren? nur ein Besuch. Lohnt keine weiteren Gedanken.
YandexBot/3.0,YandexDirect/3.0 und YandexImages/3.0
User-agent-string: Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)
Es gibt weitere User-agent-string, in denen YandexBot durch eine der folgenden Bezeichnung ersetzt ist:
- YandexImages/3.0
- YandexVideo/3.0
- YandexMedia/3.0
- YandexBlogs/0.99
- YandexFavicons/1.0
- YandexWebmaster/2.0
- YandexPagechecker/1.0
- YandexImageResizer/2.0
- YandexDirect/3.0
- YandexDirect/2.0
- YandexMetrika/2.0
- YandexNews/3.0
- YandexCatalog/3.0
- YandexAntivirus/2.0
- YandexZakladki/3.0
- YandexMarket/1.0
Die YandexBot gehören zu einer der größten europäischen Internet-Firmen, die die Russlands beliebteste Suchmaschine betreiben.
robots.txt
Die robots.txt wird im Standard beachtet. Folgendes Beispiel stammt von yandex.com:
User-agent: Yandex
Crawl-delay: 2 # specifies a 2 second timeout
# oder
User-agent: *
Disallow: /search
Crawl-delay: 4.5 # specifies a 4.5 second timeout
Aussperren? Manchmal bin ich mir nicht sicher, ob es von Vorteil ist, bei Yandex gelistet zu sein. Der Traffic aus dem ost-europäischenh Raum ist selten guter Traffic.
Die Echtheit der YandexBots kann über die IP-Adresse und Reverse DNS geprüft werden. Die Namen der echten Bots enden mit yandex.ru, yandex.net oder yandex.com.
Yeti/1.0 und Yeti/1.1
User-agent-string: Yeti/1.0 (NHN Corp.; http://help.naver.com/robots/)
User-agent-string: Yeti/1.1 (Naver Corp.; http://help.naver.com/robots/)
Der Yeti oder NaverBoot ist ein koreanischer Crawler. Wegen meiner nicht vorhandenen Koreanisch-Kenntnisse kann ich nicht viel zu der Suchmaschine sagen.
robots.txt
Der Bot versteht zusätzlich den Parameter Allow:
User-agent: *
Disallow: /
User-agent: NaverBot
Allow: /
User-agent: Yeti
Allow: / User-agent: NaverBot
Crawl-delay: 30
User-agent: Yeti
Crawl-delay: 30
Aussperren? Gute Frage. Die wenigen Zugriffe lassen sich an einer oder zwei Händen abzählen. Lohnt keinen weiteren Gedanken.
Y!J-BRJ/YATS crawler
User-agent-string: Y!J-BRJ/YATS crawler (http://help.yahoo.co.jp/help/jp/search/indexing/indexing-15.html)
Japanischer Crawler von Yahoo. Auch hier gibt es wieder Sprachprobleme.
Aussperren? Nicht der Rede Wert.
Neueste Kommentare