
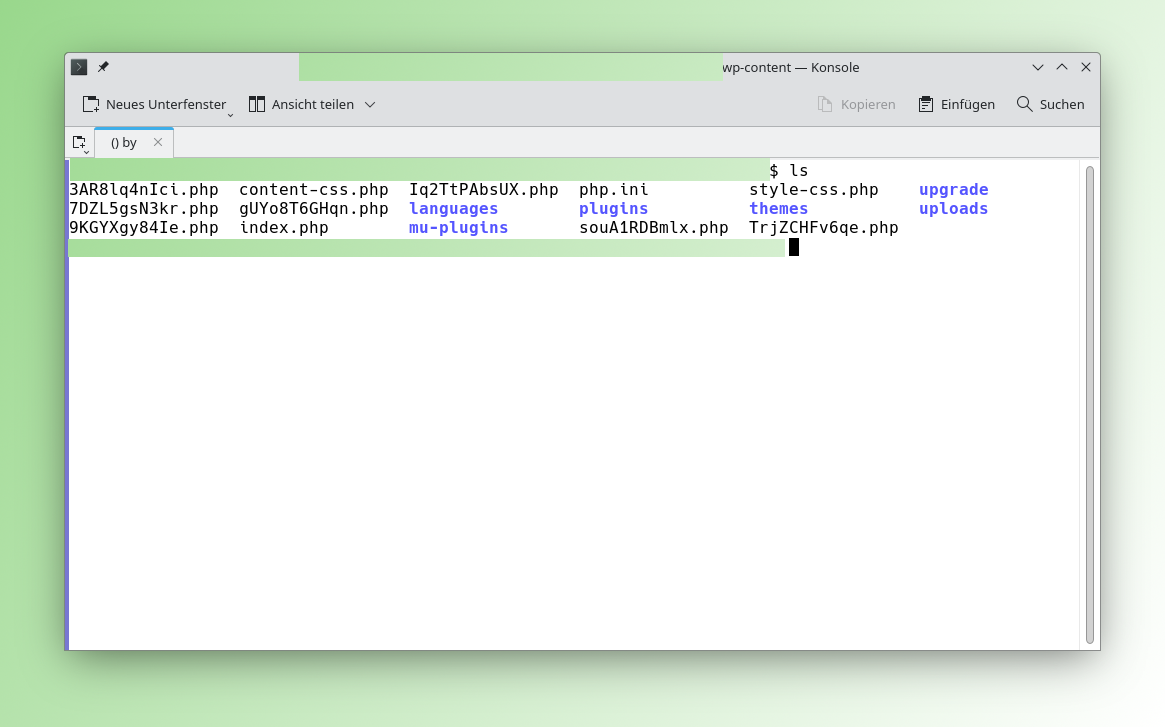
Auch auf meinen Seiten waren die Angriffe erfolgreich. Dabei gehen die Angreifer ziemlich rücksichtslos mit der Web-Seite um und bemühen sich nicht, die Angriffe zu […]
WeiterlesenKategorie: WEB 2.0

Plugin Kirchenjahr evangelisch
Vor vier Jahren habe ich mir ein kleines WordPress-Plugin zum Liturgischen Kalender geschrieben. Darin verwende ich eine Funktion create_function, die nun obsolet ist und nicht […]
WeiterlesenLiturgischer Kalender als WP Plugin
Durch Zufall habe ich den Liturgischen Kalender und ein kleines PHP-Script für die Einbindung in die eigene Web-Seite gefunden. Daraus habe ich heute Abend ein […]
WeiterlesenHerrnhuter Losungen in MySQL / MariaDB importieren
Das Hernnhuter Losungen Widget zeigt unter WordPress die Losung des Tages in einer Seitenleiste an. Bei der Anpassung und Überarbeitung für 2019 kam mir die […]
WeiterlesenWordPress unter Apache2 absichern
Bisher habe ich den WordPress dadurch abgesichert, dass ich einen Login nur über einen VPN zugelassen habe. Darüber hinaus verlasse ich mich auf lange, zufällige […]
Weiterlesen
DSVGO
[vgwort line=“99″ server=“vg05″ openid=“e20e2f0b17f04ca0b25902c244688a63″] Nun hat sie Sie und mich erwischt, die Datenschutz-Grundverordnung oder die VERORDNUNG (EU) 2016/679 DES EUROPÄISCHEN PARLAMENTS UND DES RATES vom […]
WeiterlesenPhishing: Sparkasse
Derzeit sind vermehrt Pishing Mails mit einer angeblicch notwendigen Bestätiung der Kontodaten unterwegs. Gemeinsames Kennzeichen der E-Mails ist, das der Linkt zur Pishinge -Site in […]
Weiterlesen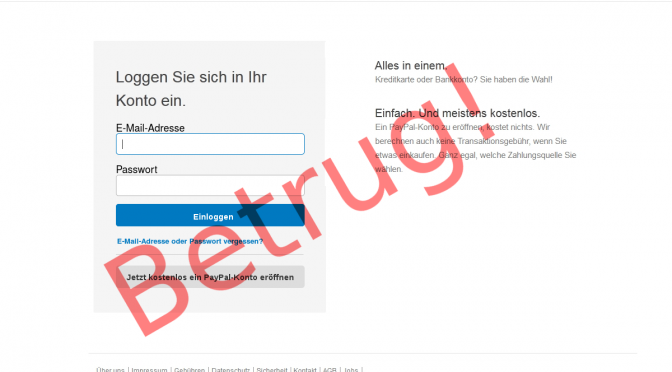
(WordPress) Blogs gehackt – Fortsetzung 1
[vgwort line=“70″ server=“vg05″ openid=“70615039bda64b63ad687aee2bbe3169″] Vor einigen Tagen habe ich über die Einbrüche in WordPress Blogs und andere Systeme berichtet. Leider – oder glücklicherweise – waren […]
WeiterlesenBeliebteste Web-Seite
Was es nicht alles gibt; unter www.beliebstewebseite.de kann jeder für Web-Seiten abstimmen. Der Crawler ist aber schon lange nicht mehr hier vorbeigekommen, das Bild der […]
WeiterlesenAngriffe auf WordPress
[vgwort line=“45″ server=“vg05″ openid=“09b8cd3fef7e4abc8f7c0a204fc313c4″] Täglich wird etwa 100 Mal von etwa 60 Rechnern versucht über die Anmeldeseite wp-login.php in dieses Blog byggvir.de einzubrechen. Die meisten […]
Weiterlesen
Neueste Kommentare